home
posts
writing as I learn
Categories
All
(9)
cs
(1)
deep learning
(5)
paper
(6)
quick intro
(1)
Tiny Recursive Models Pt. 1
a breakdown and some randomization experiments
A few months ago Hierarchical Reasoning Models (HRMs) showed remarkable ARC performance for their relatively tiny (27M) parameter count. While HRMs introduced a lot of…
Apr 11, 2026
9 min
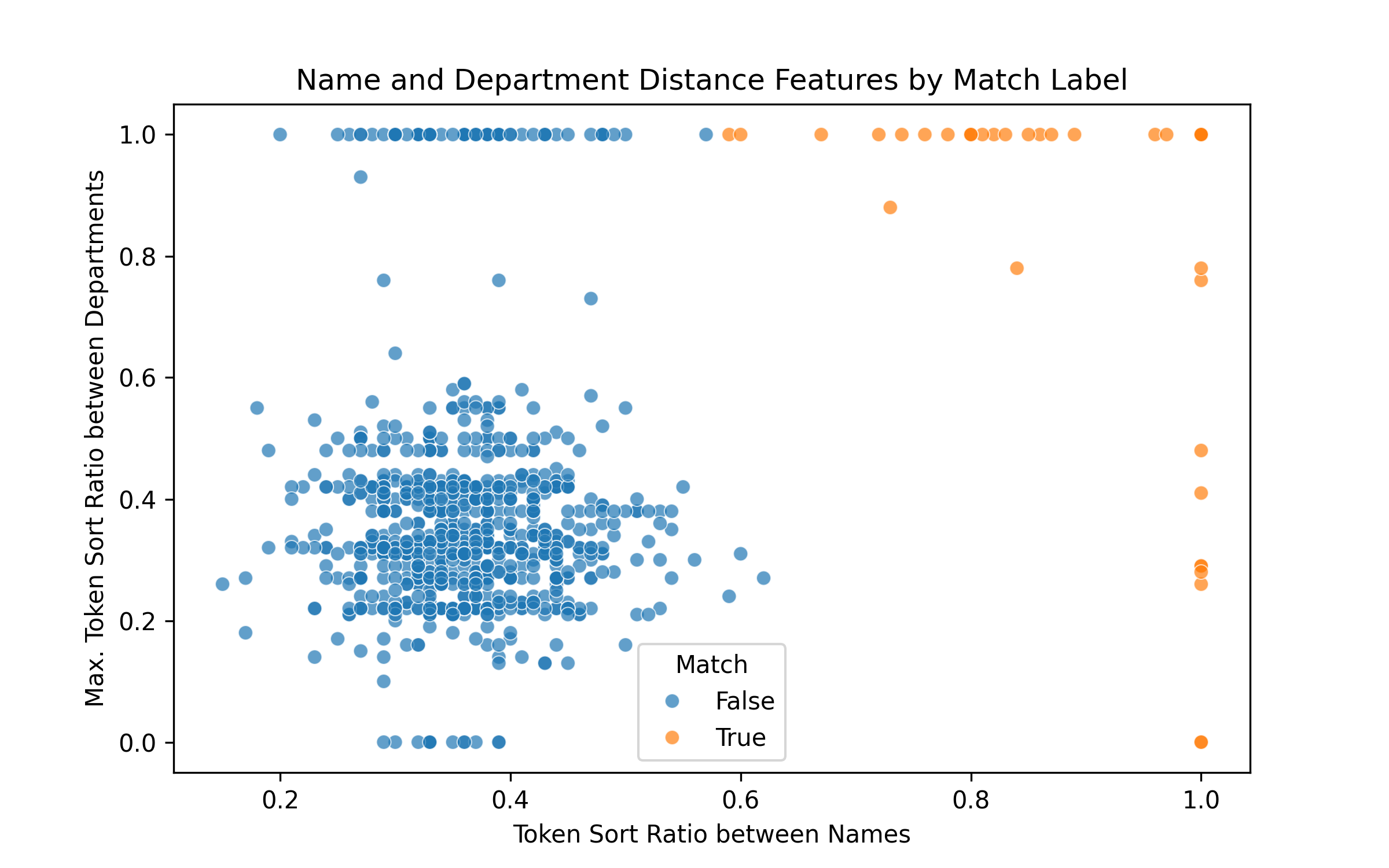
Fuzzy matching professors to their reviews
lessons from a simple ML approach
During my undergrad, I built a simple schedule planning site for my university. By the third semester I’d grown tired of using excel and learned enough javascript to code up…
Sep 9, 2025
9 min
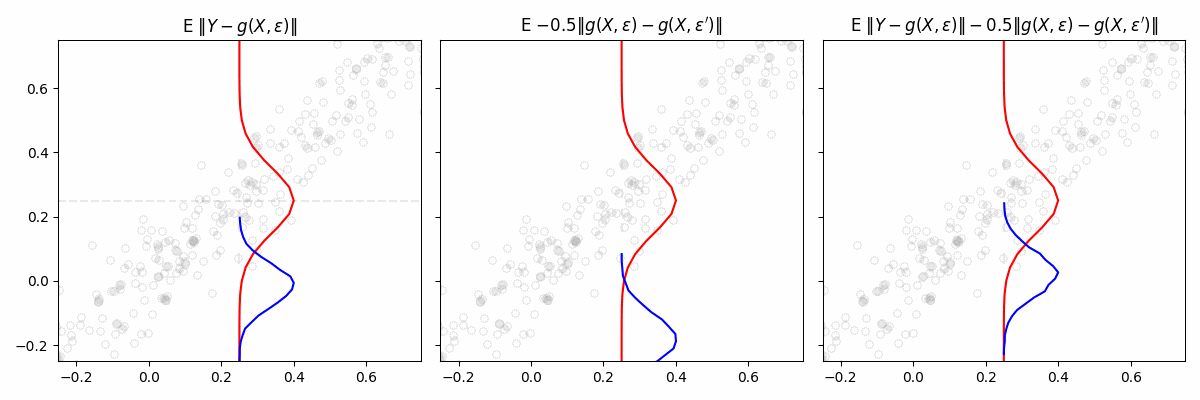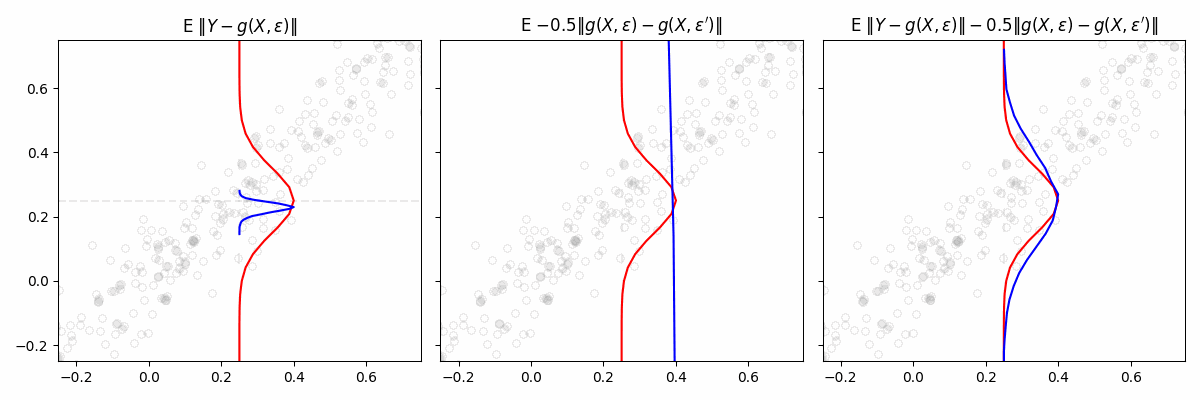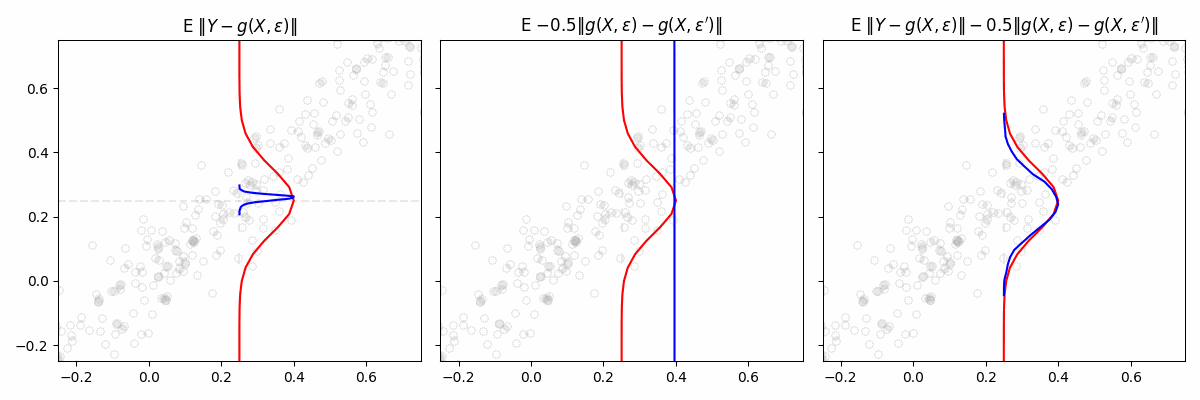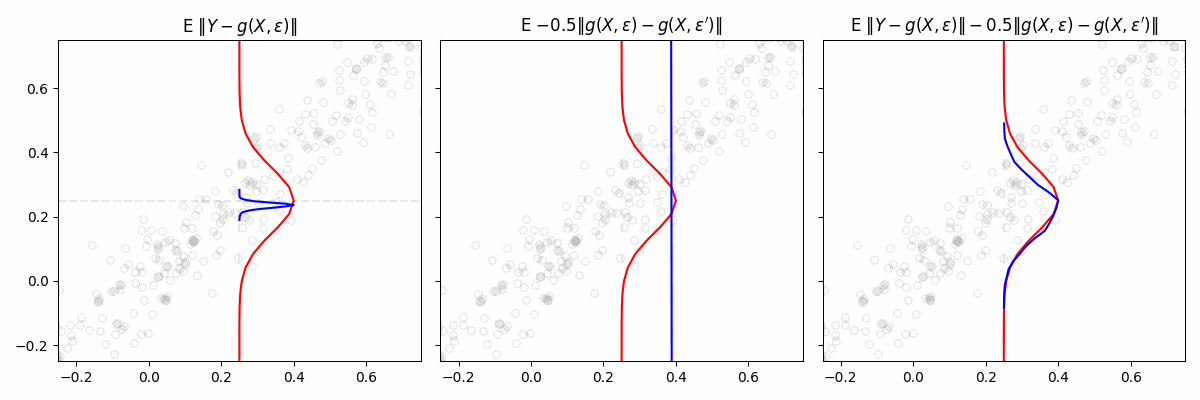
Engression
exploring a lightweight approach to distributional regression
paper
Traditional regression models predict the conditional mean
\(\mathbb E[Y∣X=x]\)
, or sometimes a few quantiles. In contrast, distributional regression attempts to learn the
en…
May 6, 2025
10 min
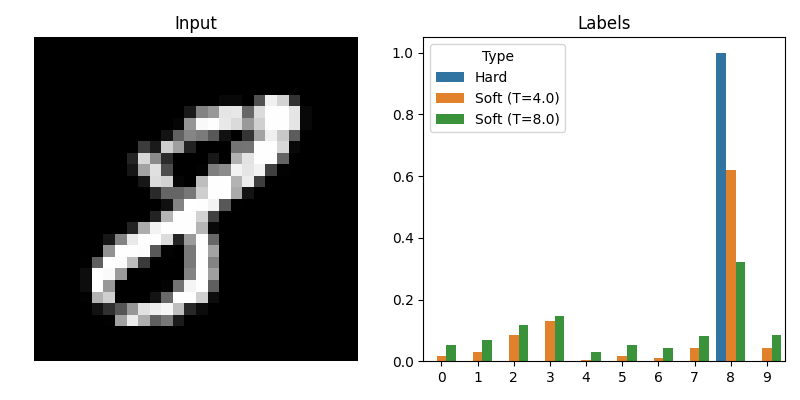
Distilling the Knowledge in a Neural Network
Revisiting and implementing part of the classical paper
deep learning
paper
This classic paper introduced
distillation
as a way of transferring knowledge from a big network teacher into a small one. The core observation is that we should use the big…
Jan 28, 2025
4 min
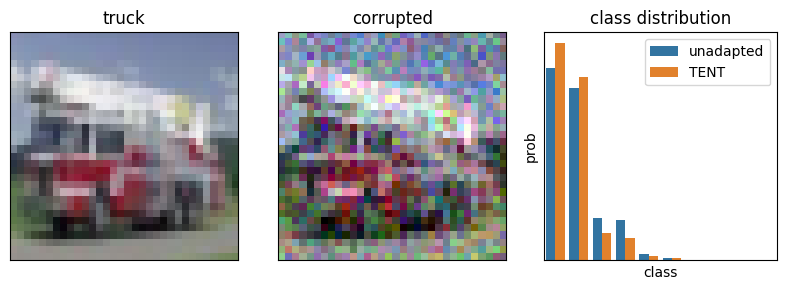
TENT: Fully Test-Time Adaptation By Entropy Minimization
An attempted (partial) paper reproduction
deep learning
paper
Once a model is deployed the feature (covariate) data distribution might shift from that seen during training. These shifts make models go out-of-distribution and worsen…
Dec 29, 2024
3 min
A Closer Look at Memorization in Deep Networks
An attempted (partial) paper reproduction
deep learning
paper
This paper argues that memorization is a behavior exhibited by networks trained on random data, as, in the absence of patterns, they can only rely on remembering examples.…
Sep 7, 2024
4 min
Approximate Nearest Cosine Neighbors
cs
quick intro
Using Random Hyperplane LSH
Aug 9, 2024
4 min
Understanding Batch Normalization
An attempted (partial) paper reproduction
deep learning
paper
The paper investigates the cause of batch norm’s benefits experimentally. The authors show that its main benefit is allowing for larger learning rates during training. In…
Jul 17, 2024
8 min
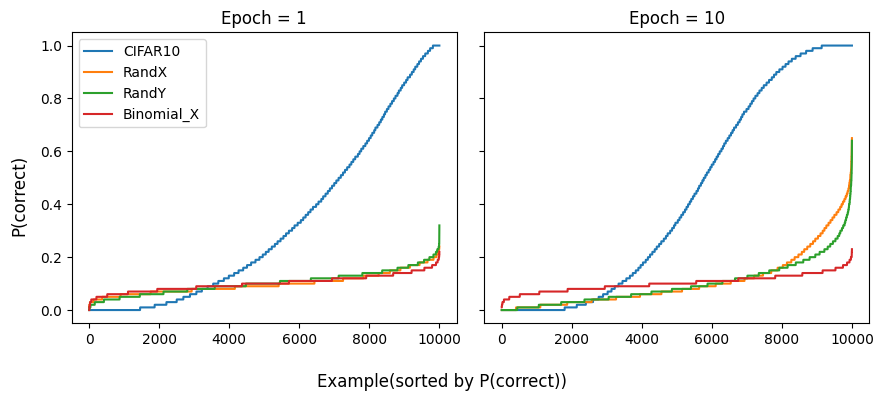
Deep Learning is Robust to Massive Label Noise
An attempted (partial) paper reproduction
deep learning
paper
The paper shows that neural networks can keep generalizing when large numbers of (non-adversarially) incorrectly labeled examples are added to datasets (MNIST, CIFAR, and…
Jun 18, 2024
4 min
No matching items